DDL - определение структуры базы данных
Разработчику
Аналитику
Тестировщику
Архитектору
Инженеру
DDL в SQL
Что такое DDL?
★ DDL (Data Definition Language) – подмножество SQL, отвечающее за определение и изменение структуры базы данных. DDL-операции работают с метаданными: создают, изменяют и удаляют таблицы, индексы, связи между таблицами и другие объекты БД. DDL как «скелет» БД – таблицы, связи и ограничения.
Структура данных включает в себя таблицы, представления, столбцы, строки, индексы, связи и ограничения. Конечно, ещё есть триггеры, хранимые процедуры, последовательности и права доступа - но об этом позже. Сначала запомним основую структуру:
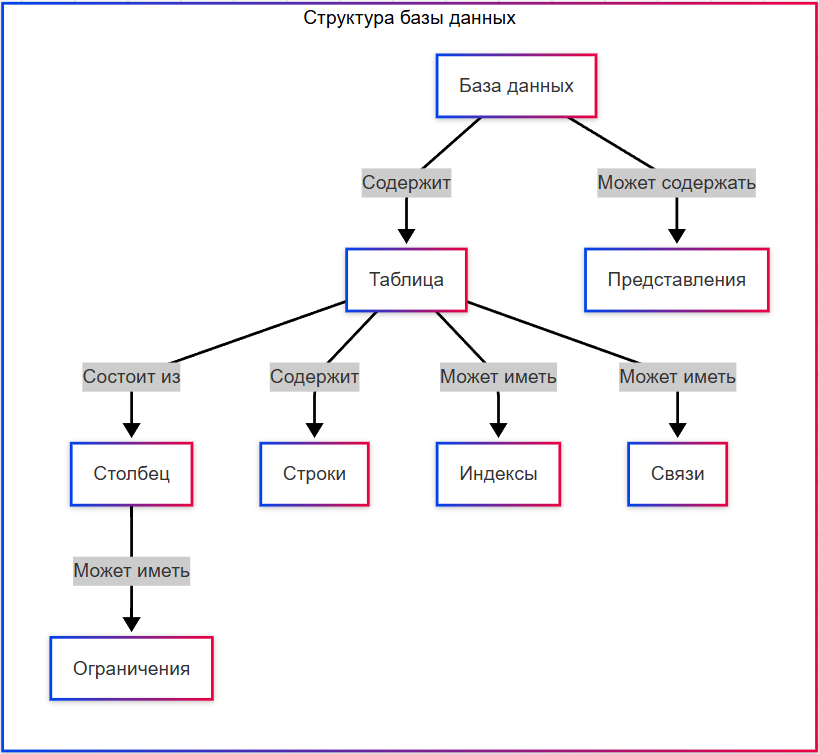
★ Таблица – основа базы данных, структура, где данные хранятся в виде строк (записей) и столбцов (полей). Имя таблицы должно быть уникальным в пределах базы данных.
★ Столбец (поле) это атрибут таблицы, определяет тип данных, которые можно хранить в таблице. У каждого столбца есть свой тип данных. Столбец может иметь ограничения (например, NOT NULL – обязательное поле).
★ Ограничения (Constraints) – «правила» для данных, которые контролируют допустимые значения в столбцах. Они защищают от некорректных данных (например, возраст не может быть отрицательным), и обеспечивают целостность базы данных.
Типы ограничений
- PRIMARY KEY (Первичный ключ) – уникально идентифицирует каждую строку в таблице. Не может быть NULL. В одной таблице может быть только один PRIMARY KEY.
CREATE TABLE users (
id INT PRIMARY KEY, -- Столбец id — первичный ключ
name VARCHAR(50)
);
- FOREIGN KEY (Внешний ключ) – связывает данные между таблицами. Обеспечивает ссылочную целостность (нельзя удалить запись, на которую есть ссылки).
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
FOREIGN KEY (user_id) REFERENCES users(id) -- user_id должен существовать в users(id)
);
- UNIQUE (Уникальность) – значения в столбце не должны повторяться. В отличие от PRIMARY KEY, может быть NULL (но только один раз).
CREATE TABLE users (
email VARCHAR(100) UNIQUE -- email должен быть уникальным
);
- NOT NULL (Запрет пустых значений) – столбец не может содержать NULL.
CREATE TABLE users (
name VARCHAR(50) NOT NULL -- имя обязательно
);
- CHECK (Проверка условия) – проверяет значение по условию.
CREATE TABLE users (
age INT CHECK (age >= 18) -- возраст ≥ 18
);
- DEFAULT (Значение по умолчанию), если значение не указано, подставляется DEFAULT:
CREATE TABLE users (
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- дата создания (текущая)
);
Индексы
★ Индексы – ускорители поиска. Индекс – это дополнительная структура, которая ускоряет поиск данных в таблице (как оглавление в книге). Без индекса СУБД проверяет каждую строку (полный перебор), что медленно. А с индексом – сразу переходит к нужным данным. К примеру, вот поиск по email без индекса и с индексом:
-- Без индекса (медленно)
SELECT * FROM users WHERE email = 'test@mail.com';
-- Создаём индекс
CREATE INDEX idx_email ON users(email);
-- Теперь поиск по email быстрый
Индекс создаёт отсортированную копию столбца с указателями на строки. При поиске СУБД использует индекс (бинарный поиск), а не сканирует всю таблицу. Это можно использовать допустим, при частом поиске по столбцу, сортировке и JOIN между таблицами.
Важно: Индексы замедляют вставку новых данных и обновление данных в индексируемом столбце. При INSERT, UPDATE, DELETE СУБД должна обновлять все индексы, связанные с затронутыми столбцами.
Индекс в SQL — это структура данных, которая создается для одного или нескольких столбцов таблицы с целью повышения производительности запросов. Индекс помогает механизму базы данных (БД) находить строки, соответствующие определенному запросу, обеспечивая быстрый доступ к данным. Это ускоряет операции поиска и фильтрации (WHERE, JOIN, ORDER BY).
Без индекса СУБД выполняет полное сканирование таблицы (Full Table Scan) — перебор всех строк. С индексом — поиск становится похож на бинарный поиск в отсортированной структуре, что значительно ускоряет выборку.
С индексом:
- Фильтрация (WHERE) быстро находит нужные строки;
- Сортировка (ORDER BY) не требуется, если есть индекс по этим полям;
- Соединение (JOIN) ускоряет связывание таблиц;
- Уникальность (UNIQUE) - индекс позволяет проверять уникальность быстро.
Индексы работают путем создания отдельной структуры данных, которая содержит копии индексируемых столбцов в отсортированном порядке. При выполнении запроса механизм БД ищет в индексе строки, соответствующие условиям запроса, а затем извлекает фактические данные из таблицы. Индексы хранятся отдельно от таблиц и могут быть довольно большими, поэтому важно учесть, что они занимают место на диске.
Важно следить за тем, какие индексы используются, а какие — нет. Поэтому важно не создавать лишних индексов, особенно если запросы к определённым столбцам редки. Не нужно индексировать всё подряд - только те столбцы, которые реально участвуют в запросах. Для убеждения в том, что индекс действительно используется, нужно использовать оптимизацию и проверку плана выполнения.
Но об оптимизации и планах мы поговорим позже.
Какие бывают виды индексов?
- Одностолбцовые индексы создаются по одному столбцу, к примеру:
CREATE INDEX idx_name ON users(name);
- Многостолбцовые / составные индексы (Composite Indexes) создаются по нескольким столбцам:
CREATE INDEX idx_name_age ON users(name, age);
Порядок столбцов в составном индексе важен.
Например, индекс (name, age) поможет при запросах типа:
SELECT * FROM users WHERE name = 'Хлоя' AND age > 30;
но может не помочь, если запрос будет таким:
SELECT * FROM users WHERE age > 30;
-
Кластеризованный индекс определяет физический порядок хранения данных в таблице. В одной таблице только один такой индекс. Если часто запрашиваются данные по какому-то диапазону (например, по дате), то кластеризованный индекс по этой колонке может существенно ускорить выполнение запроса.
-
Некластеризованный индекс хранит указатель на данные, но не влияет на их расположение. В одной таблице их может быть несколько.
-
Временный индекс используется для разовых задач (например, месячных отчётов), при ETL-процессах, где нужно временно ускорить выборку и после окончания задачи - удалить индекс, чтобы не замедлять операции записи.
К примеру, можно создать индекс, использовать его и удалить после использования - и всё в одном запросе:
-- Создать индекс
CREATE INDEX idx_temp_report ON sales(report_date);
-- Использовать его
SELECT * FROM sales WHERE report_date BETWEEN '2025-01-01' AND '2025-01-31';
-- Удалить после
DROP INDEX idx_temp_report;
Основные команды DDL:
| Команда | Описание |
|---|---|
| CREATE | Создаёт объекты БД (таблицы, индексы, представления и т. д.) |
| ALTER | Изменяет структуру существующих объектов |
| DROP | Удаляет объекты из БД |
| TRUNCATE | Удаляет все данные из таблицы, но сохраняет её структуру |
| RENAME | Переименовывает объекты (не во всех СУБД) |
Создание объектов
Создание базы данных:
CREATE DATABASE MyDB;
Создание таблицы:
Представим, что мы хотим создать таблицу, и зададим:
id– первичный ключ с автоинкрементом (автоувеличением идентификатора);username– обязательное поле (NOT NULL);email– уникальное значение (UNIQUE);age– проверка, что возраст>= 18(CHECK);created_at– дата создания (по умолчанию текущая).
Запрос будет следующим:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
age INT CHECK (age >= 18),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Для ускорения поиска, мы сделаем индекс по полю username:
CREATE INDEX idx_username ON users(username);
Изменение структуры
Добавление столбца:
ALTER TABLE users
ADD COLUMN phone VARCHAR(20);
Удаление столбца:
ALTER TABLE users
DROP COLUMN age;
Изменение типа данных столбца:
ALTER TABLE users
MODIFY COLUMN email VARCHAR(150);
Добавление ограничения (constraint):
ALTER TABLE users
ADD CONSTRAINT chk_age CHECK (age >= 16);
Добавление первичного ключа (на столбец Id):
ALTER TABLE Users
ADD CONSTRAINT PK_Users_Id PRIMARY KEY (Id);
Добавление внешнего ключа (из таблицы Orders в таблицу Users):
ALTER TABLE Orders
ADD CONSTRAINT FK_Orders_Users
FOREIGN KEY (UserId) REFERENCES Users(Id);
Переименование таблицы:
ALTER TABLE Users
RENAME TO Users_old;
Удаление объектов
Удаление базы данных:
DROP DATABASE MyDB;
Удаление таблицы:
DROP TABLE users;
Удаление индекса:
DROP INDEX idx_username ON users;
Удаление ограничений (включая ключи):
ALTER TABLE Orders
DROP CONSTRAINT FK_Orders_Users;
Очистка таблицы(удаление всех записей, но не самой таблицы):
TRUNCATE TABLE users;